Petite vidéo intéressante sur la façon de créer son propre ordinateur Mac (pas sûr qu’au final on s’y retrouve au niveau du prix et de la difficulté, mais intéressant au moins pour la partie technique). La partie assemblage et matériel n’est pas la plus importante, mais je retiens la partie installation de MacOS sur l’ordinateur (et les pilotes).
Archives de catégorie : Informatique
TrueCrypt : fiable mais à corriger
TrueCrypt, logiciel connu, ou à connaître pour garder une sécurité de ses informations.
Le principe est simple, crypter ses données. Pour cela plusieurs méthodes, crypter un disque dur entier (système auquel il faudra saisir son mot de passe au démarrage de l’ordinateur, ou disque de données), ou une partition virtuelle sous la forme d’un fichier dans lequel on mettra toutes nos informations confidentielles.
Un premier audit a été réalisé, et celui-ci confirme la fiabilité et la confiance dans ce logiciel, il n’y a pas de backdoor dans TrueCrypt ! Donc on peut y mettre ses données, à moins de laisser trainer son mot de passe ou sa clé privée, personne n’y accèdera, et quand bien même sous la torture (oui, je sais que ce que vous cachez est précieux et nous devons y accéder !) vous devez donner votre mot de passe, vous avez la possibilité de configurer le stockage chiffré pour dévoiler un autre endroit de stockage suivant le mot de passe donné !
Toutefois des problèmes ont été trouvé, des manques de commentaires ou fonctions obsolètes, mais franchement rien de grave quant au fait de savoir que nos données sont normalement bien en sûreté.
A suivre et surtout à utiliser (disponibles sous tous les OS).
Heartbleed : amusez-vous à comprendre la faille

Cloudflare a mis en ligne une page très intéressante pour les petits curieux au sujet de Heartbleed avec à disposition un site qui permettait d’essayer de récupérer la clé soit disante accessible via cette faille.
N’hésitez pas à y jeter un oeil, ne serait-ce que pour la culture de la sécurité informatique des serveurs.
Réussir son développement
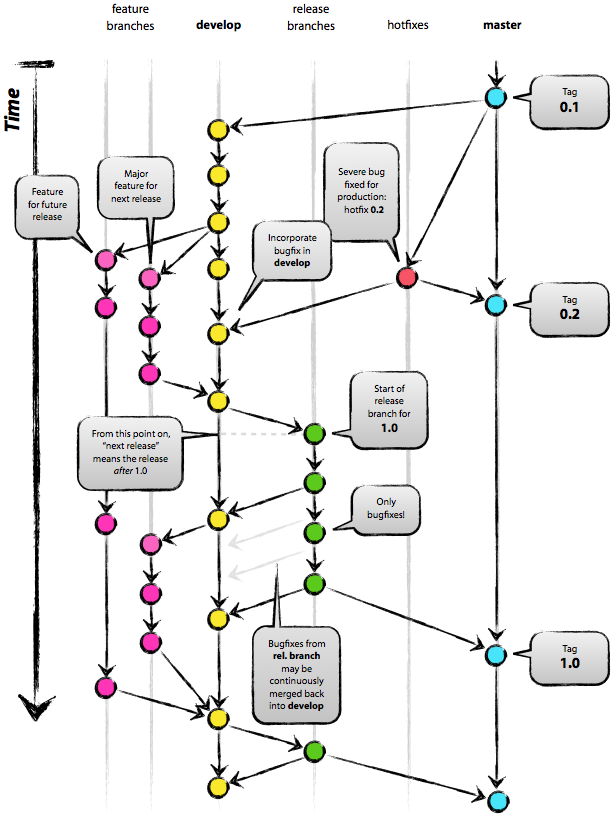
avec GitHub précise cet article, mais en le lisant, je dirais plutôt réussir son développement tout court.
En effet un article intéressant à lire et que je recommande, tellement il reprend des notions parfois évidentes mais non respectées. On devrait toujours avoir au moins 2 branches git par exemple (master = prod, develop = en cours…). L’article a également un passage sur les tests.
Lien sur la philosophie à avoir sur la gestion de branches d’un espace de travail (relative à git mais peut être utilisée par n’importe quel autre outil de versioning).
Ah les tests… combien de fois j’ai pu répéter et signaler l’importance de tests (unitaires et fonctionnels) dans un développement. Combien de fois il a pu arriver après avoir rajouté une fonction, qu’une ancienne ne fonctionne plus car on n’avait pas testé les fonctions de l’appli. Bref faites des tests et exécutez-les ! Vous n’en gagnerez que du temps, plus votre application se développera, plus vous devez gagner du temps sur le test des fonctions antérieures à votre développement. Vous ne devez pas cliquer, écrire, soumettre un formulaire, vous devez l’automatiser dès la première fois que vous voulez tester votre application. Une fois votre test fait, ce seront ces actions que vous n’aurez pas à faire manuellement, et qui se feront donc en quelques secondes avec leur résultat.
Les développeurs codent mal
C’est ce qui en ressort aujourd’hui.
C’est le ressenti de Leslie Lamport, directeur de la recherche pour Microsoft, et j’avoue partager son point de vue. Alors qu’à l’école on nous apprend de l’analyse, des méthodes de réflexion, de la logique bien avant de connaître un langage et programmer, on se demande pourquoi quand un étudiant code pour lui et dans une entreprise oublie tout et file dans le code direct avant de tout mettre sur papier.
Un développeur gagnerait pourtant du temps à analyser son projet ou son application en premier lieu. J’aime beaucoup l’image de l’architecte, pour moi tout se résume à ça. Avant de faire une maison on ne pose pas une brique puis on verra après, on a un plan, qu’on respecte ou non, mais qui nous permet d’avoir une directive. En informatique, cela doit être pareil.
Développeurs, analysez, réfléchissez, puis codez ! Vous gagnerez en qualité de code.
Supprimer de manière définitive et sans trace vos données sous Linux

En ces périodes de confidentialité de données (voir article précédent), il est conseillé quand vous avez des données sensibles de les supprimer de manière sécurisée (non mettre dans la corbeille n’est pas supprimer un fichier, et vider la corbeille n’est pas non plus la manière définitive de supprimer un fichier).
Je donne un exemple simple mais efficace de supprimer un fichier sous Linux avec la commande shred installée de base sous Debian (certainement disponible sur les autres distributions).
shred -n 7 -u -z <nom du fichier>
Eh oui tout bêtement, alors pourquoi s’en priver ?
-n 7 : réécrit 7 fois des données dans le fichier (par défaut 3, mais on n’est jamais trop prudent, 7 me semble un bon compromis)
-u : supprime le fichier à la fin des réécritures
-z : termine le processus avant la suppression par remplir le fichier de 0 pour masquer la manipulation
Cette commande me prend moins de 10 minutes pour un fichier de 7.4 Go pour 7 passes, donc rien d’alarmant et on peut s’en servir sans risquer de perdre une journée.
Les plus curieux peuvent rajouter un -v pour afficher la progression.
Heartbleed : mettez à jour vos serveurs SSL/TLS !

Une faille, visiblement très critique, compromet la sécurité de nos informations transmises sur Internet, si vous avez des serveurs et que vous les administrez, il y a de grande chance pour que ceux-ci soient vulnérables au niveau de SSL/TLS.
Pour expliquer rapidement, une attaque de type buffer overflow (dépassement de tampon) qui consiste à envoyer des données dans une certaine taille et un certain format permet d’accéder aux données qui ont pourtant été transmises de manière chiffrées sur le serveur.
Vous pouvez corriger cette faille de manière très simple, un apt-get update && apt-get upgrade ou yum update devrait corriger le problème. Pensez à redémarrer les services utilisant les librairies ou dans le doute redémarrez complètement le serveur avec un reboot.
Et tester finalement votre serveur à cette adresse pour vérifier que vous avez corrigé le problème.
Plus d’informations sur Heartbleed bug.
Améliorer la géolocalisation dans Piwik
Si vous avez décidé d’utiliser Piwik pour analyser les statistiques de votre site, voici une petite procédure pour améliorer la finesse de la géolocalisation.
On va configurer notre serveur Linux (Debian ou Ubuntu) en PECL qui est la méthode recommandée (accessible uniquement si vous avez la main sur votre serveur type serveur dédié, pour un mutualisé, il faudra passer par la méthode PHP).
On se connecte donc en SSH, et on installe les librairies et outils qui vont bien :
apt-get install php-pear php5-geoip php5-dev libgeoip-dev
pecl install geoip
On va ensuite installer la base de données. Une fois les librairies installées, on va dans Piwik > Paramètres > Géolocalisation, et tout en bas, nous pouvons télécharger la base de données gratuite. Si vous avez un message d’erreur, vous pouvez le télécharger manuellement à cette adresse, il vous faudra alors depuis SSH faire un wget par exemple, puis placer le fichier dans <chemin piwik>/misc. Pensez à renommer le fichier GeoLiteCity.dat en GeoIPCity.dat.
Dernière étape, l’activation dans notre serveur. L’installation de la librairie a certainement dû configurer automatiquement PHP. Modifier le fichier correspondant (/etc/php5/fpm/conf.d/20-geoip.ini ou /etc/php5/conf.d/geoip.ini par exemple) pour avoir :
extension=geoip.so
geoip.custom_directory=<chemin piwik>/misc
On relance apache, ou fpm suivant votre installation, retournez dans l’administration Piwik, et cochez PECL qui devrait indiqué en vert installé.

Pensez à configurer la mise à jour automatique (mensuelle par exemple) en ajoutant le lien donné plus haut dans l’URL de téléchargement.
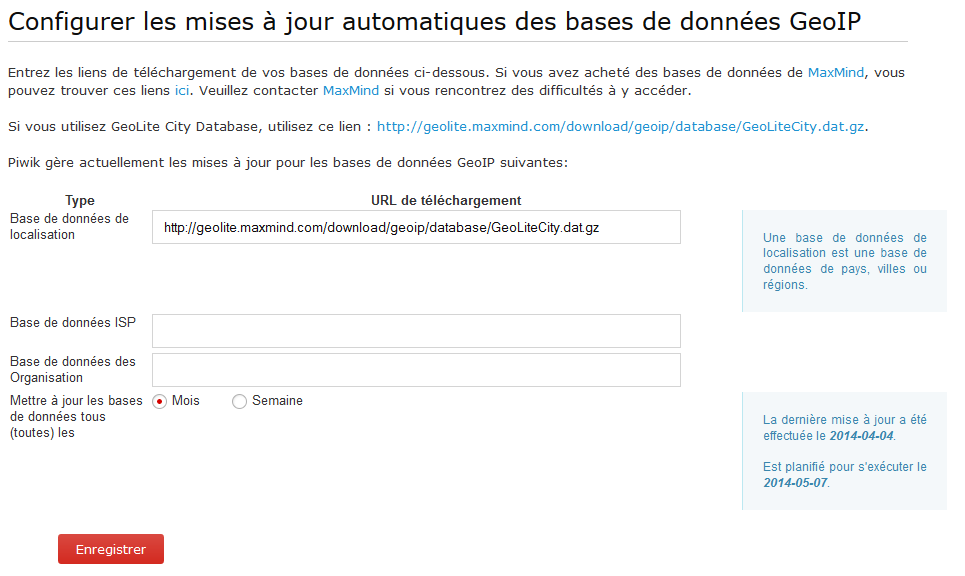
Si vous voulez tester la mise à jour du fichier, il faudra forcer le cron de Piwik, pour cela il vous suffit de vous rendre à l’adresse http://<URL PIWIK>/misc/cron/archive.php?token_auth=<TOKEN> en remplaçant <TOKEN> par votre token super utilisateur que vous trouverez dans la page Utilisateurs de Piwik.
Ubuntu One s’arrête
Voilà, c’est fait, prenez vos clics et vos clacs, il n’y a plus rien à voir ! Vous pouvez voir l’annonce sur le blog officiel.
Ubuntu One ferme (enfin ?) ses portes. N’ayant jamais misé dessus, je ne suis pas surpris du tout, enfin si, ma seule surprise et que cela a duré aussi longtemps. Les grands services comme Dropbox, Google Drive, MEGA ou mon petit préféré hubiC ont eu raison de lui.
Les services de stockage à l’époque se sont multipliés, et j’étais très surpris de voir Ubuntu sortir son service, déjà il fallait être sous Ubuntu pour avoir une chance d’en entendre parler, et même ceux sous Ubuntu ne l’utilisaient pas tous (j’en faisais partie). Pourquoi ne m’en servais-je pas (oui j’inverse le sujet, le verbe et le complément) ? Car j’avais à l’époque du mal à croire à la pérennité de ce service, Ubuntu pour moi était un système, qui en plus avait (a ?) du mal à se rentabiliser, alors confier mes données à un service qui ne sait pas où aller, pas tellement confiance.
Donc si vous y avez des données, pensez à les récupérer vous avez jusqu’au 31 juillet.
Je parlerai certainement plus tard pourquoi je choisis hubiC personnellement.
Qu’est-ce que l’open source ?
L’open source, ou partage des données, ou accès au code, bref… un logiciel gratuit ! Euh non non… on reprend tout.
Open source n’est pas forcément synonyme de gratuit. Plutôt qu’un long et fastidieux discours, voici une vidéo qui explique plutôt bien ce qu’est l’open source, l’origine, comment ça fonctionne, et ses préjugés.
Bon visionnage !
Merci à Korben